
У цій статті я розкажу як з допомогою Python та Selenium можна автоматизувати деякі задачі у веб-браузері в операційній системі Linux.
Моя проблема полягала у тому, що соцмережа LinkedIn не надає користувачам розширеного керування своїми дописами. За 5 років у мене назбиралося більше 1000 дописів, тому гортати і скролити їх всіх просто не було сенсу. Вбудований експорт даних LinkedIn теж не дав мені бажаних результатів.
Я почав думати і шукати ідеї як їх спарсити. Невдовзі штучний інтелект привів мене до вирішення цієї задачі з допомогою Selenium WebDriver для браузера Chrome.
Що таке Selenium?
Selenium – це безкоштовний інструмент з відкритим кодом для автоматизації та тестування веб-додатків, розроблений Джейсоном Хуггінсом. Інструмент складається з різних модулів: Selenium IDE, Selenium Grid, Selenium Standalone Server і Selenium WebDriver.
В основу Selenium WebDriver покладено кросплатформний веб-драйвер, який допомагає здійснювати віддалене керування браузером на основі команд на рівні операційної системи (Selenium Remote Control (RC)). Підтримуються усі доступні на сьогоднішній день браузери: Chrome, Safari, Firefox, Internet Explorer та інші. Драйвер інтегрується з іншими додатками, наприклад Jenkis.
Selenium підтримує чимало мов програмування – C#, Java, JavaScript, Node.js, Python , PHP, .NET, Perl, Ruby, Groovy, Scala. Сумісний з усіма операційними системами – Windows, Linux, MacOS, Android.
Застосовують Selenium – розробники, тестувальники, фахівці з кібербезпеки, системні адміністратори для автоматизації різноманітних задач у браузері, наприклад веб-скрапінгу та парсингу, автоматичного виконання скриптів та сценаріїв.
Selenium WebDriver підтримує такі команди:
- Команди браузера: get, getTitle, getCurrentUrl.
- Команди навігації в браузері: назад, вперед, до, оновити.
- Команди WebElement: clean, click, getText, sendKeys.
- Команди FindElements: findElement() з параметром як локатор або об’єкт запиту.
Веб-скрапінг стрічки LinkedIn з допомогою Selenium WebDriver: покрокове керівництво
1. Найперше, треба завантажити та встановити Chromedriver останньої версії:
https://chromedriver.chromium.org/downloads
https://googlechromelabs.github.io/chrome-for-testing/
Розпакувати драйвер потрібно в системну папку: /usr/bin/
2. Тепер треба встановити браузер Google Chrome Stable і всі необхідні компоненти та бібліотеки до нього:
sudo apt-get install google-chrome-stable sudo apt-get install libnss3 sudo apt-get install libnss3-dev
3. Далі створюємо файл з розширенням python зі скриптом, який треба автоматизувати.
Користуючись підказками штучного інтелекту, пройшовши велику кількість виправлень, мені вдалося прийти до робочої версії Python-скрипту, який автоматично скролить і парсить стрічку дописів користувача LinkedIn в файл HTML, який потім можна відкрити у будь-якому браузері і переглянути.
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.action_chains import ActionChains
import time
# Шлях до chromedriver
chromedriver_path = '/usr/bin/chromedriver'
# Створення екземпляру браузера
options = webdriver.ChromeOptions()
options.binary_location = "/usr/bin/google-chrome-stable"
options.add_argument(f"webdriver.chrome.driver={chromedriver_path}")
driver = webdriver.Chrome(options=options)
# Перехід на сторінку входу в LinkedIn
driver.get("https://www.linkedin.com/login")
# Автоматичне введення облікових даних для входу в акаунт
email_input = driver.find_element(By.ID, 'username')
email_input.send_keys("xxx@xxxxxxxx")
password_input = driver.find_element(By.ID, 'password')
password_input.send_keys("xxxxxxxxxxxxxxxxxxxxxxxx")
login_button = driver.find_element(By.XPATH, '//button[@type="submit"]')
login_button.click()
# Очікування завантаження сторінки LinkedIn
WebDriverWait(driver, 10).until(EC.title_contains("LinkedIn"))
# Перехід на сторінку з дописами LinkedIn вказаного користувача
driver.get("https://www.linkedin.com/in/username/recent-activity/all/")
# Автоматичне прокручування сторінки
def scroll_to_bottom():
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
# Зачекайте, поки loader не зникне
WebDriverWait(driver, 10).until_not(EC.visibility_of_element_located((By.XPATH, '//div[@class="artdeco-loader"]')))
# Почекайте, поки не завантажаться нові дописи
WebDriverWait(driver, 10).until(EC.presence_of_all_elements_located((By.XPATH, '//div[contains(@class, "feed-shared-update-v2")]')))
# Початкова кількість дописів перед спробою прокрутки
initial_post_count = len(driver.find_elements(By.XPATH, '//div[contains(@class, "feed-shared-update-v2")]'))
# Лічильник помилок при спробах прокрутки
error_count = 0
# Таймаут для завершення прокрутки після виявлення, що нові дописи не завантажуються
timeout = 100 # Можете задати свій бажаний таймаут
# Прокрутка сторінки для завантаження нових дописів
while True:
try:
scroll_to_bottom()
current_post_count = len(driver.find_elements(By.XPATH, '//div[contains(@class, "feed-shared-update-v2")]'))
if current_post_count == initial_post_count:
error_count += 1
if error_count > 2:
break # Якщо не завантажено нових дописів протягом кількох спроб, вийти з циклу
else:
initial_post_count = current_post_count
error_count = 0 # Скидання лічильника помилок при кожному новому дописі
# Пройдемося по кожному допису та скопіюємо посилання
posts = driver.find_elements(By.XPATH, '//div[contains(@class, "feed-shared-update-v2")]')
for post in posts:
# Знаходимо елемент меню керування для кожного допису
control_menu = post.find_element(By.XPATH, './/div[contains(@class, "feed-shared-update-v2__control-menu")]')
# Спробуємо клікнути на меню керування за допомогою ActionChains
ActionChains(driver).move_to_element(control_menu).click().perform()
# Зачекати, щоб меню з'явилося (опційно, ви можете адаптувати таймаут)
WebDriverWait(driver, 5).until(EC.presence_of_element_located((By.XPATH, './/div[contains(@class, "feed-shared-update-v2__control-menu")]')))
# Знаходимо кнопку "Copy link to post"
copy_link_button = post.find_element(By.XPATH, './/button[contains(@aria-label, "Copy link to post")]')
# Спробуємо клікнути на кнопку "Copy link to post" за допомогою ActionChains
ActionChains(driver).move_to_element(copy_link_button).click().perform()
# Зачекати, щоб меню зникло (опційно, ви можете адаптувати таймаут)
WebDriverWait(driver, 5).until_not(EC.presence_of_element_located((By.XPATH, './/div[contains(@class, "feed-shared-update-v2__control-menu")]')))
except Exception as e:
pass # Продовжити спроби прокрутки навіть у разі помилок
# Отримати HTML сторінки з дописами
html_content = driver.page_source
# Зберегти HTML у файл
with open("linkedin_posts.html", "w", encoding="utf-8") as file:
file.write(html_content)
# Закриття браузера після завершення
driver.quit() 👉 Завантажити готовий скрипт на нашому GitHub>>
Результати
Таким чином мені вдалось на повному “автоматі” вивантажити всю свою стрічку дописів LinkedIn 5 річної давності з повним збереженням верстки, медіаконтенту, посиланнями, вертикальною прокруткою. Такий веб-документ легко можна скопіювати та повторно відкрити, переглянути, дослідити. Я думаю, що подібним чином можна вивантажувати історію дописів й інших учасників LinkedIn, якщо їх сторінки відкриті.

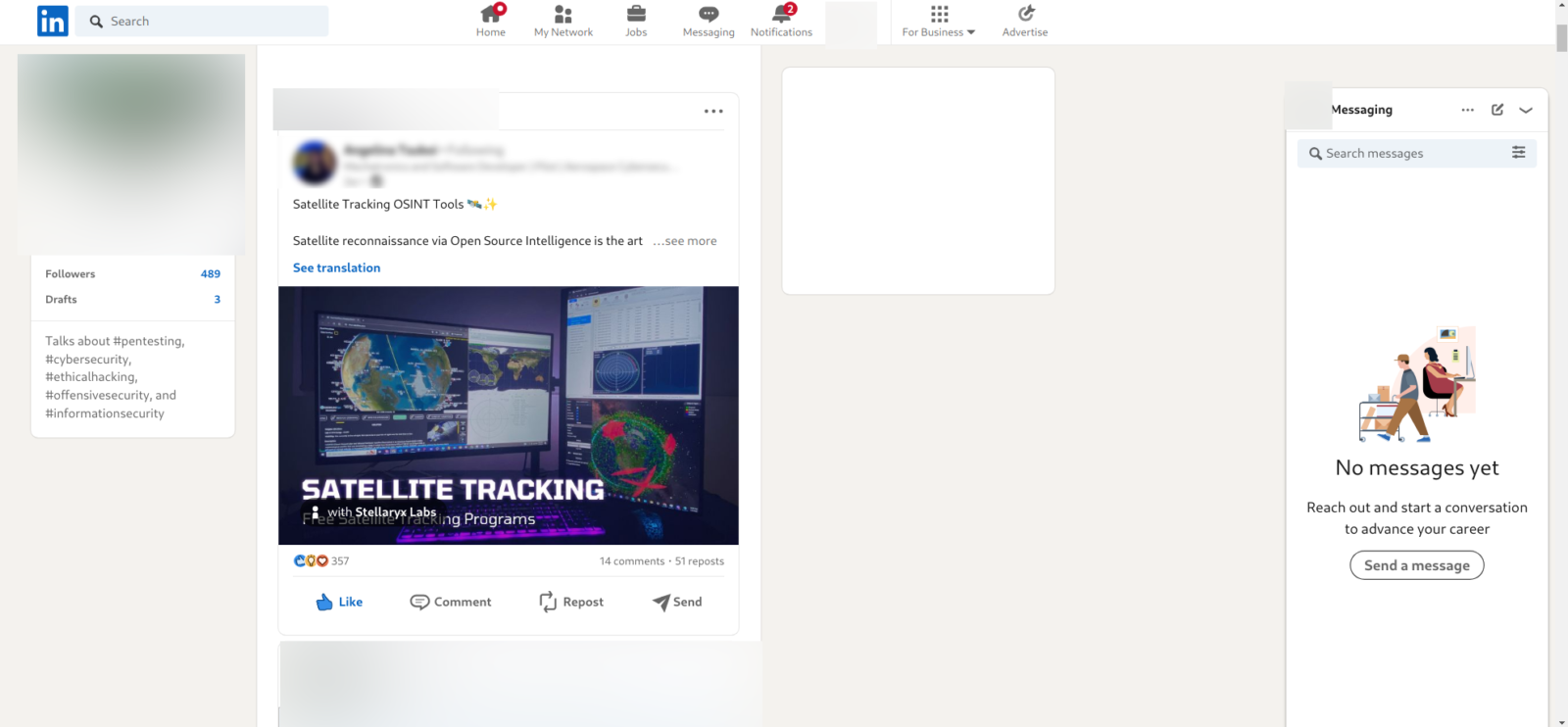
Selenium – надзвичайно корисний та потужний інструмент автоматизації.
Експерементуйте з ним і відкриєте для себе безліч нових можливостей!
Автор: © Konrad Ravenstone, KR. Laboratories Research





